1-X75-LDB
Session 1 : Introduction aux bases de donnees
1 Introduction aux bases de données
1.1. Pourquoi étudier l’histoire des bases de données ?**
Comprendre l’évolution des bases de données, c’est comprendre comment l’humanité structure l’information pour administrer, compter, prévoir, décider.
Chaque étape historique répond à une même tension :
- le réel déborde,
- l’humain tente de le contenir dans des symboles,
- les systèmes se perfectionnent pour éviter que le chaos ne revienne.
L’histoire des bases de données n’est donc pas technique au départ : elle est sociale, économique et cognitive.
1.2. Préhistoire : de la marque à la donnée (–20 000 → –3 000)
1.2.1. Les premières traces
Les humains utilisent :
- des bâtons entaillés
- des ossements marqués (ex. l’os d’Ishango)
- des cailloux ou jetons


Ces systèmes permettent de représenter des quantités ou des différences. Ce ne sont pas encore des “données” : ce sont des indices stabilisés.
1.2.2. La logique sous-jacente
- Stocker → pour se souvenir
- Représenter → pour transmettre
- Recompter → pour vérifier
C’est la fonction fondamentale de toute base de données.
1.1.3. Antiquité : écriture, comptabilité, administration (–3 300 → 500)
1.3.1. Les tokens sumériens → le cunéiforme
Les jetons d’argile (compter le grain, le bétail, les dettes) deviennent des pictogrammes pressés dans l’argile. La comptabilité invente l’écriture.

1.3.2. Les registres impériaux
Égypte, Mésopotamie, Chine, Rome :
- recensements
- cadastres
- inventaires
- listes militaires
- comptes fiscaux
Les premiers “systèmes d’information” étaient administratifs, pas littéraires.
1.3.3. La table comme principe
On voit apparaître : lignes, colonnes, cases. Structure + répétition = base de données rudimentaire.
1.4. Moyen Âge → Lumières : systèmes comptables (1200 → 1800)
1.4.1. La comptabilité en partie double
Introduction des colonnes “débit” / “crédit”. C’est une forme primitive de relation entre opérations.
1.4.2. Standardisation du tableau
Les livres de comptes deviennent :
- structurés
- normalisés
- audités
Le tableau devient outil de fiabilité.
1.5. Mécanisation du calcul (1642 → 1900)
1.5.1. Premières machines
- Pacaline
- Machine de Leibniz
- Arithmomètre
Elles calculent, mais ne “stockent” pas. Le stockage reste sur papier.

1.5.2. Les cartes perforées
Jacquard (1801) → instructions sur cartes.

Hollerith (1890) → recensement américain par cartes.
 IBM naît de cette révolution.
IBM naît de cette révolution.
Les cartes perforées sont la première base de données mécanisée.
Et voici le clavier:

1.6. Naissance de l’informatique et premières bases (1945 → 1969)
1.6.1. Le concept d’information (Shannon)
Claude Shannon (1948) transforme l’information en quelque chose de mesurable, comme on mesure la distance ou le poids. Avant, “information” était un concept vague. Il en fait une quantité mathématique précise: le bit. L’unité de base. Un bit = une réponse oui/non. Pile ou face = 1 bit d’information.
Shannon prouve que l’information peut être stockée, transmise et mesurée comme n’importe quelle grandeur physique, posant les fondations de l’ère numérique.
1.6.2. Ordinateurs à mémoire
Machines capables de :
- stocker
- calculer
- effacer
- réutiliser
1.6.3. Bases hiérarchiques et navigables
- IMS (IBM) : données organisées en arbres
- CODASYL : modèle réseau
Ces systèmes sont performants mais peu flexibles.
Les données sont prisonnières de la structure.
- Pour retrouver une information, on doit parcourir la structure.
- Si la structure change, les programmes doivent être modifiés.
- Peu de flexibilité pour faire des requêtes variées.
1.7. 1970 : Le modèle relationnel (Codd)
Moment fondateur.
1.7.1. Les principes
- la donnée = table
- un enregistrement = tuple
- une colonne = attribut
- la contrainte = vérité
- manipulations = algèbre relationnelle
1.7.2. Les avantages
- indépendance des données
- flexibilité
- cohérence
- normalisation
Le relationnel sépare la façon de stocker de la façon d’interroger. C’est une révolution conceptuelle, pas seulement technique.
1.8. L’ère des SGBDR industriels (1979 → 2000)
1.8.1. Les pionniers
- Oracle (1979)
- Ingres
- IBM DB2
1.8.2. SQL devient normatif
Le langage unifie l’industrie. Les SGBDR deviennent le cœur des systèmes financiers, administratifs, logistiques.
1.8.3. Le data warehouse
Naissance de l’analytique moderne :
- index avancés
- requêtes complexes
- dénormalisation stratégique
1.9. Rupture : Big Data & NoSQL (2005 → 2015)
1.9.1. Explosion des volumes
Google, Amazon, Facebook dépassent les limites des SGBDR centralisés.
1.9.2. Les nouveaux modèles
- clé-valeur (Redis)
- documents (MongoDB)
- colonnes (Cassandra)
- graphes (Neo4j)
Chaque modèle privilégie un usage. On renonce volontairement à certaines garanties pour scaler.
1.10. NewSQL & systèmes distribués relationnels (2012 → …)
1.10.1. Retour au relationnel, mais distribué
- Google Spanner
- CockroachDB
- Yugabyte
Objectif : réunir cohérence + scalabilité horizontale.
1.10.2. Convergence
On garde le SQL, on change l’architecture.
1.11. Aujourd’hui : écosystèmes polyglottes
Les entreprises combinent plusieurs types de bases selon les besoins :
- relationnel pour l’intégrité
- graphes pour les liens
- colonnes pour l’analytique
- documents pour la flexibilité
Il n’y a plus une vérité : il y a une adéquation.
Synthèse — Points à retenir pour le cours
- La donnée est d’abord un outil administratif avant d’être numérique.
- Les structures tabulaires existent bien avant l’informatique.
- Les premiers systèmes informatiques étaient hiérarchiques ou réseau.
- Le relationnel (Codd) reste la pierre angulaire de la discipline.
- SQL est un standard industriel depuis les années 80.
- Les modèles NoSQL répondent à des besoins de scalabilité et de flexibilité.
- Les systèmes modernes sont hybrides et spécialisés selon l’usage.
2. Données tabulées
2.1 Qu’est-ce qu’une donnée tabulée ?
Les données tabulées sont des informations organisées sous forme de tableau. Cette structure bidimensionnelle (lignes × colonnes) rend l’information lisible, comparable et exploitable.
Caractéristiques principales
Données tabulées
- Présentées sous forme de tableau structuré
- Manipulées avec un tableur (Excel, Google Sheets…)
- Organisées en lignes et colonnes
- Permettent tri, filtrage, recherche, calcul et comparaison
Table
- Structure ordonnée contenant des données de même nature
- Ligne / enregistrement : représente une entité complète
- Colonne / attribut : représente un type d’information
- Cellule : valeur à l’intersection ligne/colonne
2.2. Exemples concrets dans la vie quotidienne
Les tableaux répondent à des principes universels de rangement, déjà présents dans le monde matériel. Ils apparaissent dans des contextes familiers, souvent sans qu’on les nomme “tableaux”.
2.2.1. Étagères
- Chaque rayon = une catégorie
- Objets similaires regroupés = colonnes
- Emplacement fixe = cellule
Alors quand on voit tout, et qu’on a de la place:
 Tout va bien.
Tout va bien.
Mais si on ne voit pas dedans, et qu’on a beaucoup:
 Ca devient vite insurmontable.
Ca devient vite insurmontable.
Et ca pourrait etre pire:

Mais avec un peu de bon sens et des etiquettes:

L’organisation reflete la realite qu’elle occupe:

Ou le debut de la maladie mentale:

2.2.2. Tiroir à couverts
- Compartiments = colonnes
- Chaque type d’ustensile a sa place
- Recherche immédiate, pas de confusion

2.2.3. Gestion du quotidien
Liste de tâches (Todo list)
- Attributs fréquents : tâche, priorité, échéance, statut
- Suivi de progression et priorisation

Ici, 2 colonnes:
- Checkbox: la tache est effectuee (oui/non)
- Intitule: la tache en question (texte)
Maintenant, si on duplique le format d’un jour:

Combien de colonnes ?
- 3
- 4
- 8
- 7+1
Calendrier mensuel
- Représentation visuelle du mois
- Structure fixe : 7 colonnes
- Donnees variables : calendrier imperial demarre le dimanche (bien sur)
Question: combien de semaine dans un mois ?
- 4
- 5
- 6
- what ?


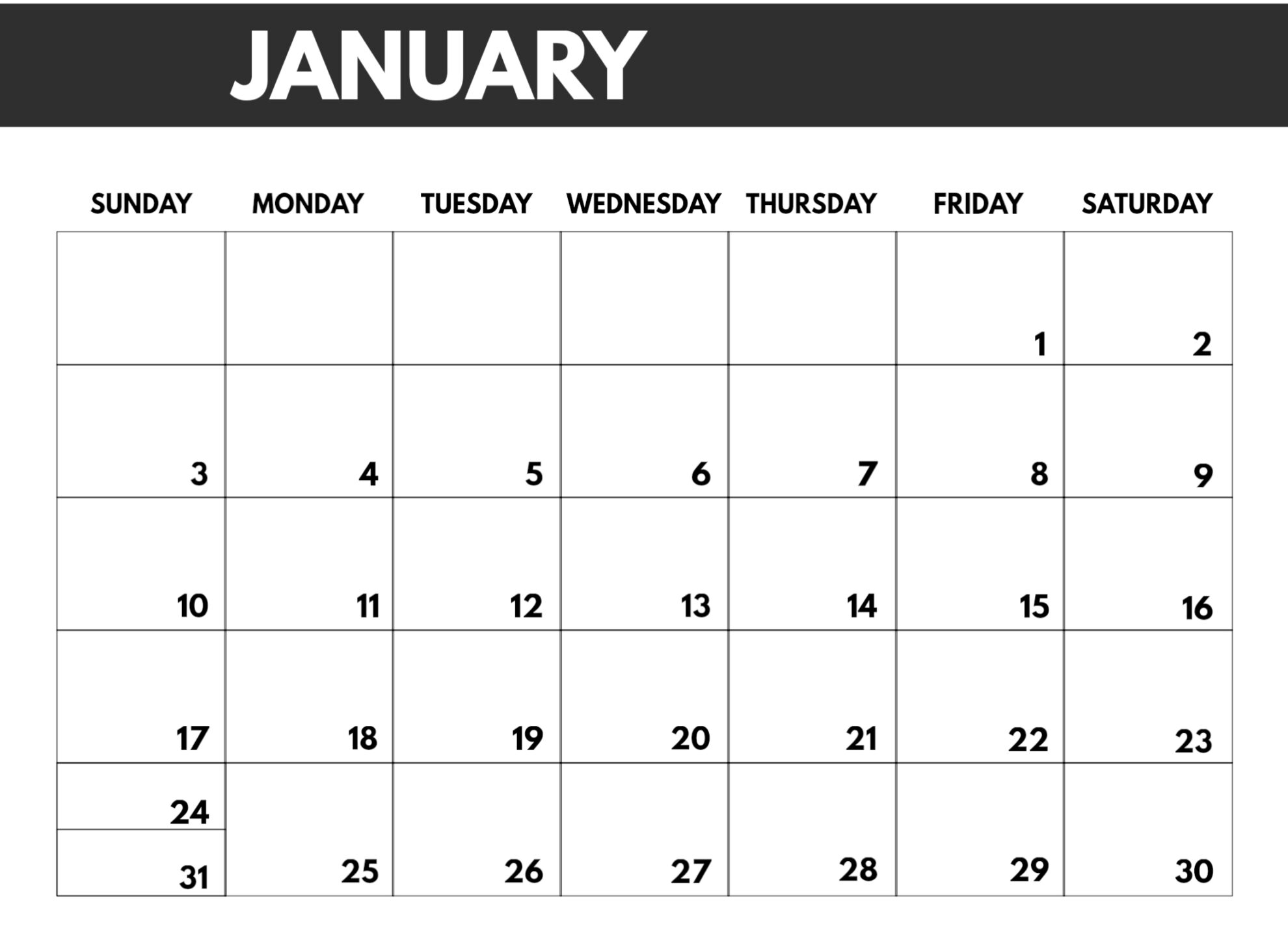
Vous avez (et vous serez encore) confronte a des questions comme celle la. Apres ce cours, vous y repondrez differement.
2.2.4. Données historiques : liste des rois mérovingiens
- Colonnes : nom, dates, événements, succession
- Permet la comparaison entre règnes
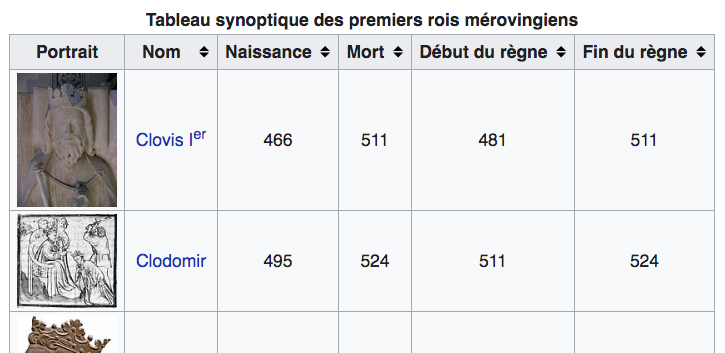
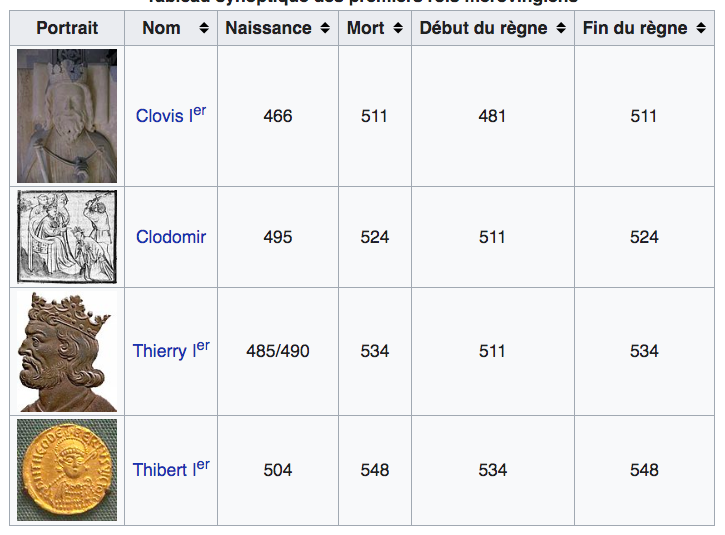
2.3. Pourquoi utiliser des tableaux ?
2.3.1. Comparaison facilitée
- Les colonnes permettent de comparer une même caractéristique
- On repère rapidement différences et similarités
- Exemple : comparer les prix de plusieurs produits
2.3.2. Recherche rapide
- Une cellule est localisée par coordonnées
- Trouver “cours de X à 14h” revient à croiser une ligne avec une colonne
2.3.3. Vue d’ensemble
- Un tableau offre une photographie globale
- Utile pour détecter tendances, anomalies ou patterns
2.3.4. Organisation logique
- Structure claire, prévisible
- Réduction des erreurs
- Standardisation naturelle
2.3.5. Exemples
Planning de cours
- Colonnes : jours, heures, salles
- Lignes : créneaux
- Permet de visualiser une semaine d’un coup

Table de multiplication
- Exemple canonique de tableau strict
- Recherche instantanée par croisement ligne/colonne
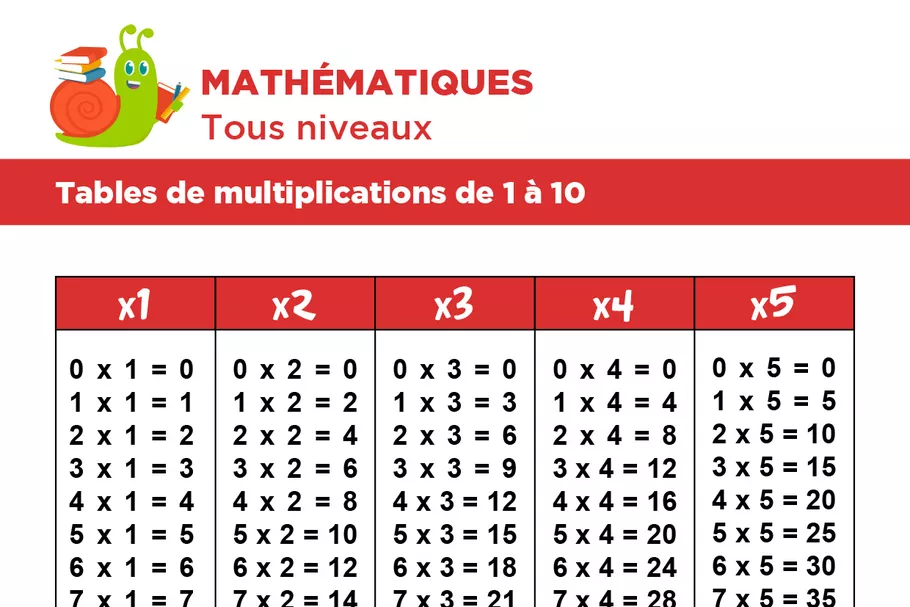
Principe commun : Organisation cohérente, répétitive et optimisée pour la recherche.
2.5. Structure formelle des données tabulées
2.5.1. Terminologie
| Terme | Description | Synonymes | Exemple |
|---|---|---|---|
| Enregistrement | Ligne représentant une entité complète | Tuple, row | Un étudiant |
| Attribut | Colonne représentant une caractéristique | Champ, field | La colonne “Âge” |
| Valeur | Donnée dans une cellule | Cellule | 18 |
| Clé | Attribut identifiant de manière unique | ID | Numéro étudiant |
2.5.2. Exemple : tableau des étudiants
| ID_Etudiant | Nom | Prénom | Âge | Classe |
|---|---|---|---|---|
| 001 | Dupont | Jean | 18 | Terminale A |
| 002 | Martin | Marie | 17 | Première B |
| 003 | Bernard | Luc | 18 | Terminale A |
Analyse :
- 3 enregistrements
- 5 attributs
- 15 valeurs
- ID_Etudiant joue le rôle de clé primaire
2.6. Principes fondamentaux des données tabulées
2.6.1. Organisation bidimensionnelle
- Lignes = entités
- Colonnes = caractéristiques
2.6.2. Cohérence des types
- Chaque colonne contient des valeurs du même type
- Permet tri, calcul et comparaison
2.6.3. Atomicité
- Une cellule = une seule information
- Éviter les données combinées (“Dupont, Martin”)
2.6.4. Accès par coordonnées
- Une cellule = intersection ligne/colonne
- Exemple : âge du 2ᵉ étudiant = [2, Âge]
2.6.5. Analyse verticale et horizontale
- Verticale : comparer un attribut (ex : tous les âges)
- Horizontale : analyser un enregistrement (profil complet)
2.6.6. Intégrité
- Un enregistrement = unique
- Une clé = garantie d’unicité
2.7. Limites des tableaux simples
Ces limites expliquent la naissance des bases de données relationnelles :
- Redondance (informations répétées)
- Difficultés de mise à jour (modification à plusieurs endroits)
- Absence de relations (liens difficiles à gérer)
- Volume (les tableurs ne passent pas à grande échelle)
Ce cours est distribué sous licence Creative Commons. Toute reproduction ou distribution à but commercial est interdite sans l’accord préalable de l’auteur.